Does the Bulk Uploader for Adx Work?
This browser is no longer supported.
Upgrade to Microsoft Border to accept advantage of the latest features, security updates, and technical back up.
Azure Data Explorer data ingestion overview
Data ingestion is the procedure used to load information records from one or more sources into a table in Azure Data Explorer. Once ingested, the data becomes available for query.
The diagram below shows the end-to-end menses for working in Azure Data Explorer and shows different ingestion methods.
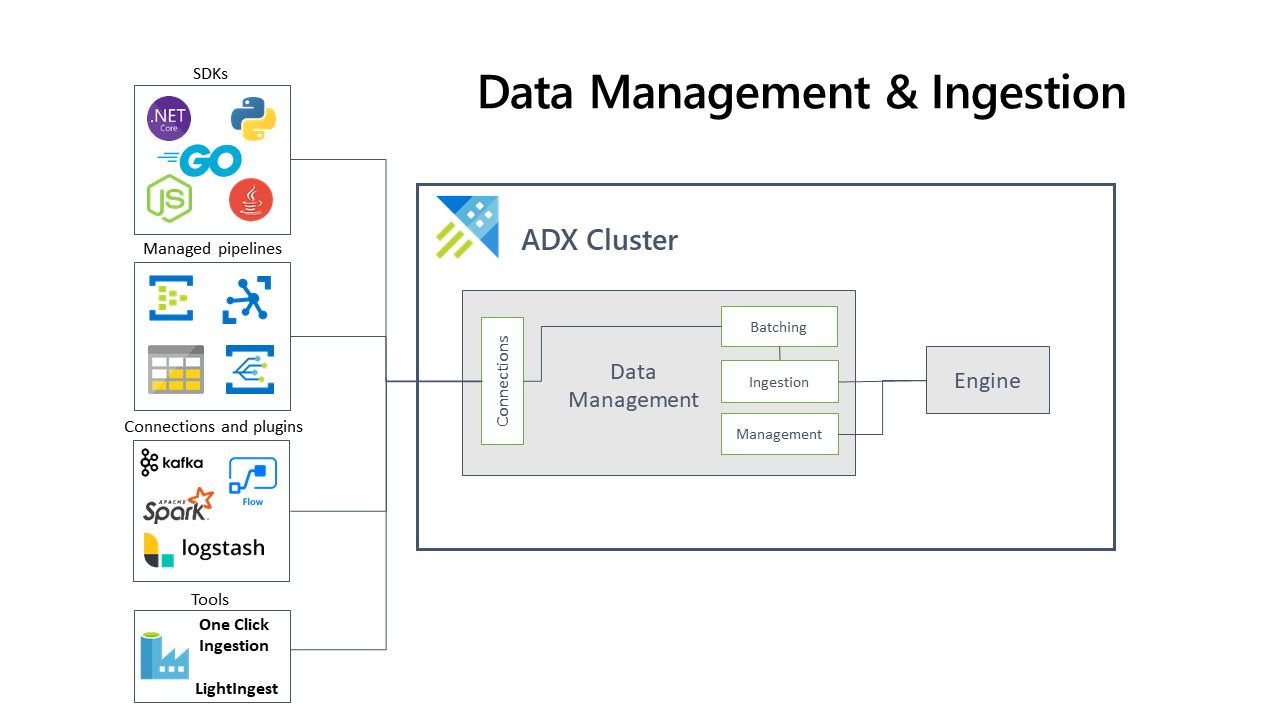
The Azure Data Explorer information direction service, which is responsible for data ingestion, implements the following procedure:
Azure Information Explorer pulls data from an external source and reads requests from a pending Azure queue. Data is batched or streamed to the Data Manager. Batch data flowing to the aforementioned database and table is optimized for ingestion throughput. Azure Data Explorer validates initial data and converts data formats where necessary. Further data manipulation includes matching schema, organizing, indexing, encoding, and compressing the information. Data is persisted in storage according to the set retentivity policy. The Information Manager and then commits the data ingest into the engine, where information technology'south available for query.
Supported data formats, backdrop, and permissions
-
Supported data formats
-
Ingestion backdrop: The properties that affect how the data will be ingested (for example, tagging, mapping, creation fourth dimension).
-
Permissions: To ingest data, the process requires database ingestor level permissions. Other deportment, such every bit query, may require database admin, database user, or table admin permissions.
Batching vs streaming ingestion
-
Batching ingestion does data batching and is optimized for high ingestion throughput. This method is the preferred and about performant blazon of ingestion. Data is batched according to ingestion properties. Pocket-size batches of data are and so merged, and optimized for fast query results. The ingestion batching policy tin can be assail databases or tables. By default, the maximum batching value is five minutes, 1000 items, or a full size of ane GB. The information size limit for a batch ingestion command is 4 GB.
-
Streaming ingestion is ongoing information ingestion from a streaming source. Streaming ingestion allows well-nigh existent-fourth dimension latency for small sets of data per tabular array. Data is initially ingested to row store, and then moved to cavalcade store extents. Streaming ingestion tin exist done using an Azure Information Explorer customer library or one of the supported data pipelines.
Azure Data Explorer supports several ingestion methods, each with its own target scenarios. These methods include ingestion tools, connectors and plugins to diverse services, managed pipelines, programmatic ingestion using SDKs, and straight access to ingestion.
Ingestion using managed pipelines
For organizations who wish to have direction (throttling, retries, monitors, alerts, and more) done by an external service, using a connector is likely the most advisable solution. Queued ingestion is appropriate for large data volumes. Azure Data Explorer supports the following Azure Pipelines:
-
Effect Filigree: A pipeline that listens to Azure storage, and updates Azure Data Explorer to pull information when subscribed events occur. For more information, come across Ingest Azure Blobs into Azure Information Explorer.
-
Event hub: A pipeline that transfers events from services to Azure Information Explorer. For more than information, see Ingest data from issue hub into Azure Data Explorer.
-
IoT Hub: A pipeline that is used for the transfer of data from supported IoT devices to Azure Data Explorer. For more data, encounter Ingest from IoT Hub.
-
Azure Information Factory (ADF): A fully managed data integration service for analytic workloads in Azure. Azure Data Factory connects with over 90 supported sources to provide efficient and resilient data transfer. ADF prepares, transforms, and enriches data to give insights that can be monitored in different kinds of ways. This service can be used as a one-time solution, on a periodic timeline, or triggered by specific events.
- Integrate Azure Data Explorer with Azure Data Factory.
- Utilize Azure Information Manufactory to copy data from supported sources to Azure Information Explorer.
- Re-create in bulk from a database to Azure Data Explorer by using the Azure Data Mill template.
- Use Azure Data Mill command activity to run Azure Information Explorer control commands.
Ingestion using connectors and plugins
-
Logstash plugin, see Ingest information from Logstash to Azure Data Explorer.
-
Kafka connector, encounter Ingest data from Kafka into Azure Data Explorer.
-
Ability Automate : An automated workflow pipeline to Azure Data Explorer. Power Automate can be used to execute a query and practice preset deportment using the query results as a trigger. See Azure Information Explorer connector to Power Automate (Preview).
-
Apache Spark connector: An open-source project that can run on any Spark cluster. It implements data source and data sink for moving information beyond Azure Data Explorer and Spark clusters. You lot can build fast and scalable applications targeting data-driven scenarios. Encounter Azure Data Explorer Connector for Apache Spark.
Programmatic ingestion using SDKs
Azure Data Explorer provides SDKs that can be used for query and data ingestion. Programmatic ingestion is optimized for reducing ingestion costs (COGs), by minimizing storage transactions during and post-obit the ingestion process.
Available SDKs and open-source projects
- Python SDK
- .NET SDK
- Java SDK
- Node SDK
- Residue API
- Get SDK
Tools
-
One click ingestion: Enables you to chop-chop ingest data by creating and adjusting tables from a wide range of source types. One click ingestion automatically suggests tables and mapping structures based on the data source in Azure Data Explorer. One click ingestion can be used for ane-time ingestion, or to define continuous ingestion via Event Filigree on the container to which the data was ingested.
-
LightIngest: A command-line utility for ad-hoc information ingestion into Azure Information Explorer. The utility tin can pull source data from a local folder or from an Azure blob storage container.
Ingest control commands
Use commands to ingest information direct to the engine. This method bypasses the Data Management services, and therefore should be used but for exploration and prototyping. Don't use this method in production or high-book scenarios.
-
Inline ingestion: A control command .ingest inline is sent to the engine, with the information to exist ingested beingness a part of the command text itself. This method is intended for improvised testing purposes.
-
Ingest from query: A control control .gear up, .suspend, .prepare-or-append, or .ready-or-replace is sent to the engine, with the data specified indirectly as the results of a query or a command.
-
Ingest from storage (pull): A control control .ingest into is sent to the engine, with the data stored in some external storage (for example, Azure Blob Storage) accessible by the engine and pointed-to by the command.
| Ingestion name | Data type | Maximum file size | Streaming, batching, direct | Most common scenarios | Considerations |
|---|---|---|---|---|---|
| One click ingestion | *sv, JSON | 1 GB uncompressed (see note) | Batching to container, local file and blob in direct ingestion | One-off, create table schema, definition of continuous ingestion with event grid, bulk ingestion with container (upwards to 5,000 blobs; no limit when using historical ingestion) | |
| LightIngest | All formats supported | ane GB uncompressed (see note) | Batching via DM or direct ingestion to engine | Information migration, historical data with adjusted ingestion timestamps, bulk ingestion (no size restriction) | Case-sensitive, space-sensitive |
| ADX Kafka | Avro, ApacheAvro, JSON, CSV, Parquet, and ORC | Unlimited. Inherits Coffee restrictions. | Batching, streaming | Existing pipeline, high book consumption from the source. | Preference may be determined past which "multiple producer/consumer" service is already used, or how managed of a service is desired. |
| ADX to Apache Spark | Every format supported by the Spark environment | Unlimited | Batching | Existing pipeline, preprocessing on Spark before ingestion, fast mode to create a prophylactic (Spark) streaming pipeline from the diverse sources the Spark environment supports. | Consider cost of Spark cluster. For batch write, compare with Azure Data Explorer data connection for Event Grid. For Spark streaming, compare with the data connection for effect hub. |
| LogStash | JSON | Unlimited. Inherits Java restrictions. | Inputs to the connector are Logstash events, and the connector outputs to Kusto using batching ingestion. | Existing pipeline, leverage the mature, open source nature of Logstash for high book consumption from the input(s). | Preference may be determined by which "multiple producer/consumer" service is already used, or how managed of a service is desired. |
| Azure Information Factory (ADF) | Supported data formats | Unlimited *(per ADF restrictions) | Batching or per ADF trigger | Supports formats that are usually unsupported, large files, can copy from over 90 sources, from on perm to cloud | This method takes relatively more time until data is ingested. ADF uploads all information to retention so begins ingestion. |
| Ability Automate | All formats supported | one GB uncompressed (see note) | Batching | Ingestion commands equally part of flow. Used to automate pipelines. | |
| Logic Apps | All formats supported | 1 GB uncompressed (see note) | Batching | Used to automate pipelines | |
| IoT Hub | Supported data formats | N/A | Batching, streaming | IoT messages, IoT events, IoT properties | |
| Event Hub | Supported data formats | North/A | Batching, streaming | Messages, events | |
| Event Grid | Supported information formats | i GB uncompressed | Batching | Continuous ingestion from Azure storage, external information in Azure storage | Ingestion can be triggered by blob renaming or hulk creation deportment |
| .Net SDK | All formats supported | 1 GB uncompressed (run into note) | Batching, streaming, direct | Write your own code according to organizational needs | |
| Python | All formats supported | 1 GB uncompressed (run across note) | Batching, streaming, direct | Write your own code co-ordinate to organizational needs | |
| Node.js | All formats supported | 1 GB uncompressed (see note | Batching, streaming, straight | Write your own code according to organizational needs | |
| Coffee | All formats supported | 1 GB uncompressed (see annotation) | Batching, streaming, direct | Write your ain code according to organizational needs | |
| Residual | All formats supported | 1 GB uncompressed (run across note) | Batching, streaming, straight | Write your own code according to organizational needs | |
| Get | All formats supported | i GB uncompressed (encounter note) | Batching, streaming, direct | Write your own code according to organizational needs |
Note
When referenced in the above table, ingestion supports a maximum file size of four GB. The recommendation is to ingest files betwixt 100 MB and 1 GB.
Ingestion process
Once you have called the virtually suitable ingestion method for your needs, exercise the following steps:
-
Prepare batching policy (optional)
The batching manager batches ingestion data based on the ingestion batching policy. Define a batching policy before ingestion. Run into ingestion best practices - optimizing for throughput. Batching policy changes can crave upwardly to v minutes to take effect. The policy sets batch limits according to three factors: time elapsed since batch creation, accumulated number of items (blobs), or total batch size. By default, settings are 5 minutes / 1000 blobs / 1 GB, with the limit get-go reached taking effect. Therefore there is commonly a v minute delay when queueing sample information for ingestion.
-
Set retentivity policy
Information ingested into a tabular array in Azure Data Explorer is subject to the tabular array's effective retention policy. Unless set on a table explicitly, the constructive retentivity policy is derived from the database's retention policy. Hot retentivity is a office of cluster size and your retention policy. Ingesting more data than you have available space will strength the first in data to cold retention.
Make certain that the database'southward retentivity policy is appropriate for your needs. If not, explicitly override it at the table level. For more information, encounter retentivity policy.
-
Create a tabular array
In order to ingest data, a table needs to be created beforehand. Use one of the following options:
- Create a table with a command.
- Create a tabular array using Ane Click Ingestion.
Note
If a record is incomplete or a field cannot exist parsed every bit the required data blazon, the corresponding table columns will be populated with zilch values.
-
Create schema mapping
Schema mapping helps bind source data fields to destination table columns. Mapping allows you to take data from different sources into the same table, based on the divers attributes. Different types of mappings are supported, both row-oriented (CSV, JSON and AVRO), and column-oriented (Parquet). In almost methods, mappings can also be pre-created on the table and referenced from the ingest command parameter.
-
Set update policy (optional)
Some of the data format mappings (Parquet, JSON, and Avro) back up simple and useful ingest-fourth dimension transformations. If the scenario requires more complex processing at ingestion, adjust the update policy, which supports lightweight processing using query commands. The update policy automatically runs extractions and transformations on ingested information on the original table, and ingests the resulting data into one or more destination tables.
-
Ingest data
You can ingest sample data into the table you created in your database using commands or the i-click wizard. To ingest your own data, you tin can select from a range of options, including ingestion tools, connectors and plugins to diverse services, managed pipelines, programmatic ingestion using SDKs, and direct access to ingestion.
Side by side steps
- Supported data formats
- Supported ingestion properties
Feedback
Submit and view feedback for
Source: https://docs.microsoft.com/en-us/azure/data-explorer/ingest-data-overview
0 Response to "Does the Bulk Uploader for Adx Work?"
Postar um comentário